from dataclasses import dataclassimport numpy as npimport numpy.typing as nptimport plotly.io as pioimport statsmodels.api as smfrom sklearn.ensemble import GradientBoostingRegressor, RandomForestRegressorfrom sklearn.linear_model import LinearRegression, LogisticRegressionfrom sklearn.neural_network import MLPRegressorfrom sklearn.tree import DecisionTreeRegressorpio.renderers.default = 'png' # comment this out for interactive plots
Dataset generation code
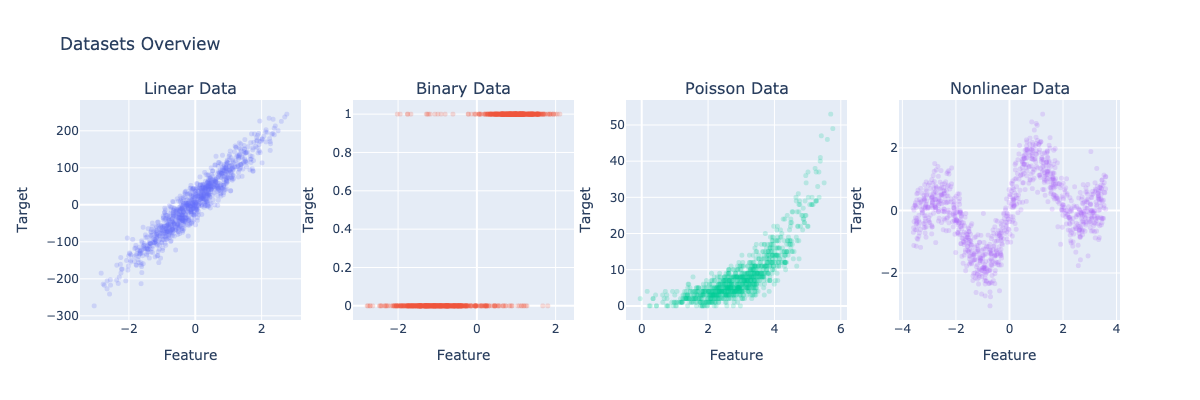
from dataclasses import dataclassfrom typing import Callableimport numpy as npimport numpy.typing as nptimport plotly.graph_objects as gofrom plotly.subplots import make_subplotsfrom sklearn.datasets import make_classification, make_regression@dataclassclass Dataset: name: str X: npt.NDArray[np.float64] y: npt.NDArray[np.float64]def make_poisson( n_samples: int, X_loc: float, coef_: float, intercept_: float, random_state: int = 0,) -> tuple[npt.NDArray[np.float64], npt.NDArray[np.float64]]: np.random.seed(random_state) X = np.random.normal(loc=X_loc, scale=X_loc / 3, size=n_samples) mu = np.exp(coef_ * X + intercept_) y = np.random.poisson(lam=mu, size=n_samples) return X, ydef f(x: npt.NDArray[np.float64]) -> npt.NDArray[np.float64]: return np.sin(x) + np.sin(2 * x)def make_nonlinear( n_samples: int, func: Callable[[npt.NDArray[np.float64]], npt.NDArray[np.float64]], X_dist: str = "uniform", X_scale: float = 1.0, noise_scale: float = 0.5, random_state: int = 0,) -> tuple[npt.NDArray[np.float64], npt.NDArray[np.float64]]: np.random.seed(random_state) if X_dist == "normal" or X_dist == "n": X = np.random.normal(scale=X_scale, size=n_samples) elif X_dist == "uniform" or X_dist == "u": X = np.random.uniform(low=-3 * X_scale, high=3 * X_scale, size=n_samples) np.random.seed(random_state + 1) noise = np.random.normal(scale=noise_scale, size=n_samples) y = func(X) + noise return X.reshape(-1, 1), ydef generate_datasets() -> list[Dataset]: datasets: list[Dataset] = [] # Linear data X, y = make_regression( n_samples=1000, n_features=1, n_informative=1, n_targets=1, noise=25.0, random_state=0, bias=7.0, ) datasets.append(Dataset("Linear Data", X, y)) # Binary data X, y = make_classification( n_samples=1000, n_features=1, n_informative=1, n_redundant=0, n_classes=2, n_clusters_per_class=1, class_sep=1.0, flip_y=0.1, random_state=0, ) datasets.append(Dataset("Binary Data", X, y)) # Poisson data X, y = make_poisson(n_samples=1000, X_loc=3.0, coef_=0.7, intercept_=-0.2, random_state=0) datasets.append(Dataset("Poisson Data", X, y)) # Nonlinear data X, y = make_nonlinear( n_samples=1000, func=f, X_dist="u", X_scale=1.2, noise_scale=0.5, random_state=0 ) datasets.append(Dataset("Nonlinear Data", X, y)) return datasetsdef plot_datasets(datasets: list[Dataset]) -> None: fig = make_subplots(rows=1, cols=4, subplot_titles=[dataset.name for dataset in datasets]) for i, dataset in enumerate(datasets, 1): fig.add_trace( go.Scatter( x=dataset.X.flatten(), y=dataset.y, mode="markers", marker=dict(size=5, opacity=0.2), name=dataset.name, ), row=1, col=i, ) fig.update_xaxes(title_text="Feature", row=1, col=i) fig.update_yaxes(title_text="Target", row=1, col=i) fig.update_layout(height=400, width=1200, title_text="Datasets Overview", showlegend=False) fig.show()
Model plot code
from typing import Any, Callableimport numpy as npimport numpy.typing as nptimport plotly.graph_objects as godef plot_model( X: npt.NDArray[np.float64], y: npt.NDArray[np.float64], xx: npt.NDArray[np.float64], y_pred: npt.NDArray[np.float64], title: str, model_label: str = "model", gt_func: Callable[[npt.NDArray[np.float64]], npt.NDArray[np.float64]] | None = None, extra_plots: list[tuple[str, npt.NDArray[np.float64], dict[str, Any]]] | None = None, xlim: tuple[float, float] | None = None, ylim: tuple[float, float] | None = None, **scatter_kwargs,): fig = go.Figure() # Scatter plot of data points scatter_kwargs = {**{"opacity": 0.4, "marker": {"size": 5}}, **scatter_kwargs} fig.add_trace(go.Scatter(x=X.flatten(), y=y, mode="markers", name="Data", **scatter_kwargs)) # Model prediction fig.add_trace( go.Scatter(x=xx, y=y_pred, mode="lines", name=model_label, line=dict(color="red", width=5)) ) # Ground truth function if gt_func: fig.add_trace( go.Scatter( x=xx, y=gt_func(xx), mode="lines", name="Ground Truth", line=dict(color="black") ) ) # Extra plots if extra_plots: for label, data, style in extra_plots: color = style.get("c", "blue") # Default to blue if 'c' is not a valid color if color in ["c", "b", "g", "r"]: # Map single-letter colors to full color names color_map = {"c": "cyan", "b": "blue", "g": "green", "r": "red"} color = color_map[color] fig.add_trace( go.Scatter( x=xx, y=data, mode="lines", name=label, line=dict(color=color, width=style.get("linewidth", 2)), ) ) # Update layout fig.update_layout( title=title, xaxis_title="Feature", yaxis_title="Target", legend=dict(x=0.02, y=0.98, bgcolor="rgba(255,255,255,0.8)"), width=900, height=700, margin=dict(l=50, r=20, t=50, b=50), # Add this line to tighten margins ) # Set axis limits if provided if xlim: fig.update_xaxes(range=xlim) if ylim: fig.update_yaxes(range=ylim) # Add grid fig.update_xaxes(showgrid=True, gridwidth=1, gridcolor="lightgray") fig.update_yaxes(showgrid=True, gridwidth=1, gridcolor="lightgray") fig.show()
Datasets preview
# Generate and plot datasetsdatasets: list[Dataset] = generate_datasets()plot_datasets(datasets)
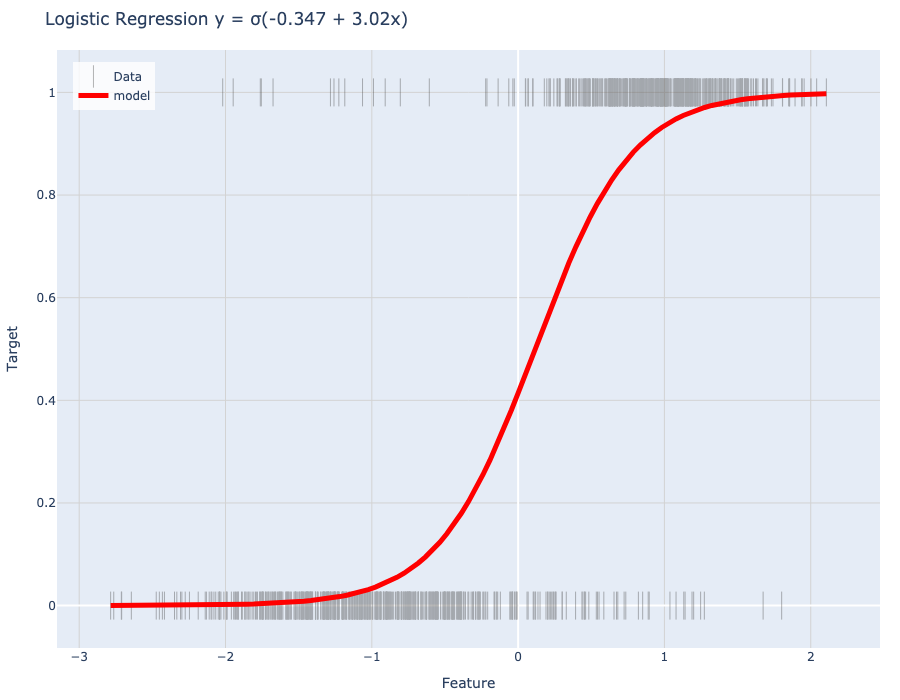
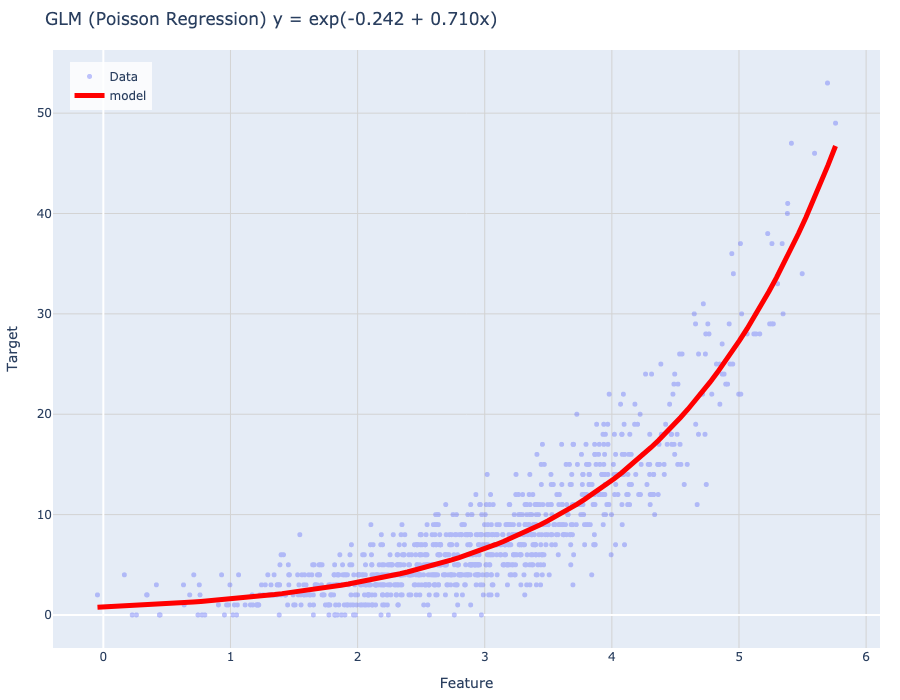
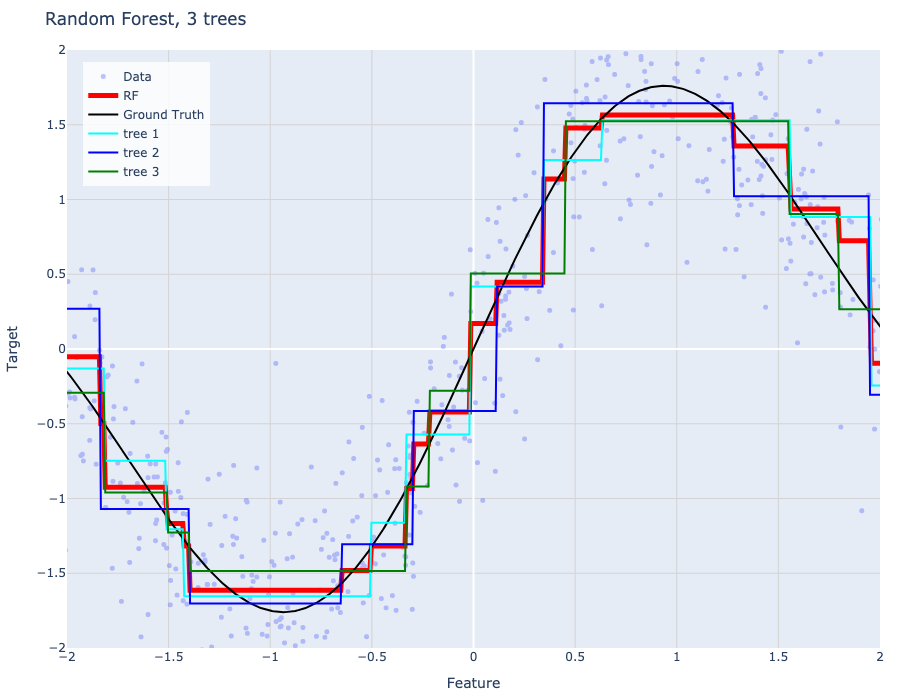
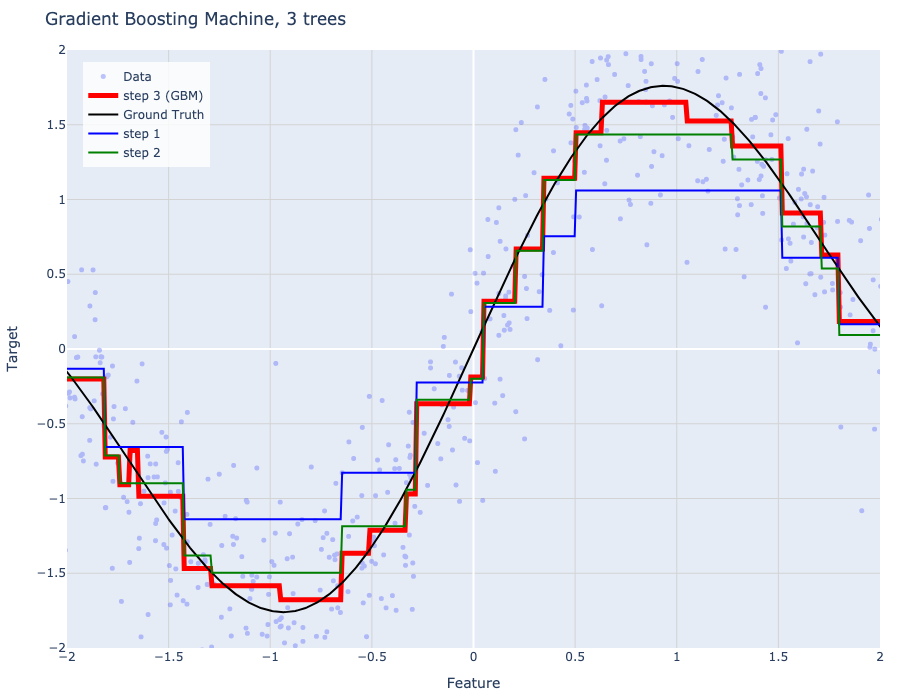
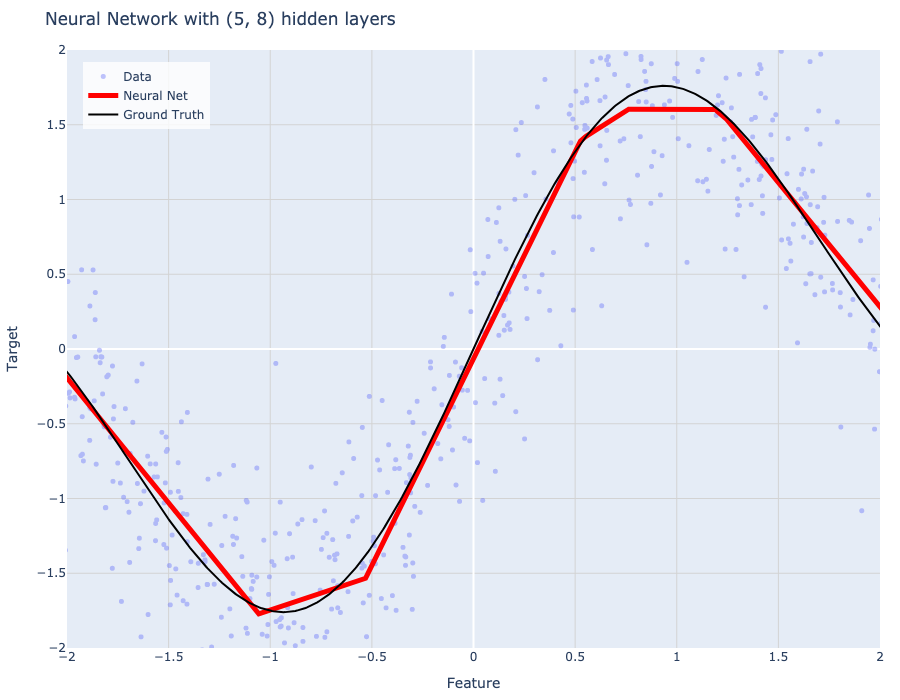
Models
Simple models
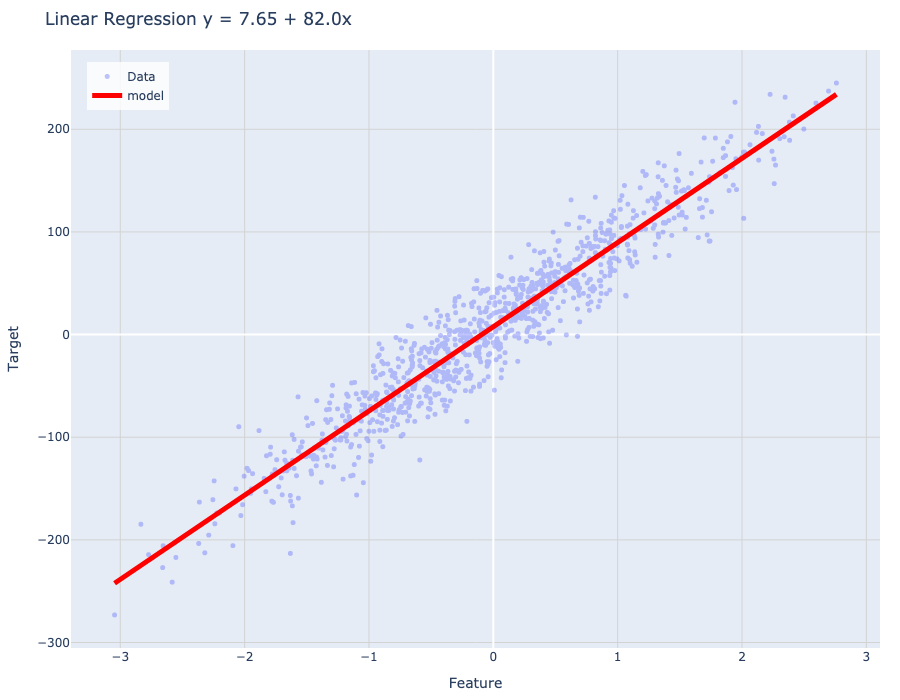
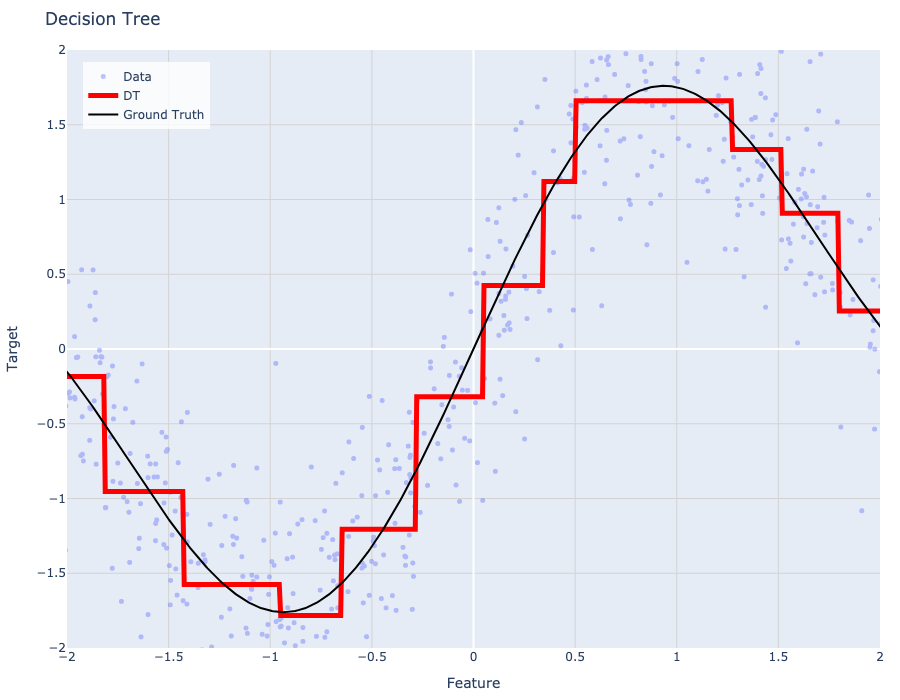
Linear regression
Code
import numpy as npimport numpy.typing as nptfrom sklearn.linear_model import LinearRegressiondef linear_regression_example(X: npt.NDArray[np.float64], y: npt.NDArray[np.float64]): lr = LinearRegression().fit(X, y) xx: npt.NDArray[np.float64] = np.linspace(X.min(), X.max(), 101) y_pred: npt.NDArray[np.float64] = lr.predict(xx.reshape(-1, 1)) title = f"Linear Regression\ny = {lr.intercept_:#.3g} + {lr.coef_[0]:#.3g}x" plot_model(X, y, xx, y_pred, title)